Paper Review
[CVPR 2018] Real-world Anomaly Detection in Surveillance Videos
하얀콩토리
2024. 3. 9. 23:33
1. Introduction
- video surveillance : to detect anomalous events
- ex) traffic accidents, crimes, illegal activties
- but, rarely occur as compared to normal activities
- 시간, 노동 줄이기 위해, 자동화된 video anomaly detection이 필요하다
1.1. Motivation and Contributions
- Real - world anomalous events
- anomaly에 해당하는 물체가 너무 다양하기 때문에 모든 이상 징후를 나열할 수 없음
- environment can change drastically over the time (different times a day)
- the boundary between normal and anomalous behaviors is often ambiguous
- 같은 행동이어도 조건에 따라 normal이거나 anomalous behavior 일수도
- ex) 거리에 차와 사람이 다니는데 그 길이 인도면 차가 anomaly, 그 길이 차도면 사람이 anomaly
- ex) 비나 눈이 오면 맑은 날씨일 때보다 정확도가 떨어짐
- 제안
- Anomaly detection should be done with minimum supervision.
- weakly labeled training videos + Multiple Instance learning(MIL)
- Weakly labeled data가 뭔데?
- previous) frame 별로 label이 존재함
- this paper) video 당 anomaly가 있다(1)/없다(0) 만 판단. 어디에 있는지는 모름
- Contributions
- weakly labeled training videos 제안
- A new large-scale video anomaly detection dataset 제안
- 1900 videos of 13 different events
- Superior performance as compared to previous approaches.
3. Proposed Anomaly Detection Method

- Bag : Videos
- Instances : Segmented videos
- video를 고정된 숫자(32)로 잘라서 가방에 넣음(Instances of bag = segments of video)
- Positive bag : 어딘가 anomalies를 포함하고 있는 video 모음
- Negative bag : 모든 구간이 normal인 video 모음
⇒ 방법론 이름이 weakly label인 이유
여기서 잠깐! C3D가 뭐야?
Learning spatiotemporal features with 3d convolutional networks
- facebook에서 만든 모델인데 3D convolution networks를 대량의 영상 데이터에 지도학습 방법으로 훈련한 모델
- 본 논문에서 13개의 different events를 분류/인식하기 위해 + feature 뽑아내기 위해 사용
3.1. Multiple Instance Learning
- temporal location(frame별 label)이 없어서 ‘헉 어떡하지’ 하다가 나온 방법
- 기존 일반적인 optimization function (SVM)

- 개별 instance x에 대해 weight와 bias를 취해 output 값을 만들어내는 hinge loss
- 근데 식을 보면 알 수 있듯이 x(video segment feature)마다 정확한 label이 필요함
- but video는 앞에서 말했듯이 frame 하나하나 label 붙이기엔 시간과 노동이 어마무시하잖아
- 그래서 SVM with MIL loss

- frame별 하나하나 score을 매기는 것이 아니라 segment별로 점수를 매기고 그 중에 max값만 loss 함수에 활용됨
3.2. Deep MIL Ranking Model
- 그래서 segment별로 점수 어떻게 매기는데?
- C3D pretrained model 사용해서 segment 별로 4096 차원의 feature 뽑고 FC layer 거쳐서 anomaly score 겟!
- 기존 ranking objective function

- 그냥 anomaly에 해당하는 segment score가 normal에 해당하는 segment score보다 높아야
- 근데 위 식은 개별 frame에 대한 것

- 고로 이렇게 weakly labeled 버전으로 바꿔줌
- positive bag(anomaly)에 있는 segment들 중 가장 최대 score를 가진 것은 아마 true positive instance일꺼고
- negative bag(normal)에 있는 segment들 중 가장 최대 score를 가진 것은 normal 상태지만 그 중에서도 anomalous segment랑 가장 비슷한 segment겠지 ⇒ false alarm 가능성 있는 친구
- 고로 목표는 이 둘의 차이를 좀 크게 해야겠다.
limitation
- anomaly 상황은 굉장히 짧은 시간에 이루어진다는 것
- positive bag에 있는 instances들의 score가 매우 sparse할 것
- video는 연속된 segment들로 이루어져 있기 때문에, anomaly score가 video segment들 사이에 smooth하게 되어야 할 것. 그래야 자연스러움


- 고로 2개의 constraints 추가해서 나온 최종 objective function
- temporal smoothness term
- 인접한 video segment들의 점수 차이가 크지 않게
- sparsity term
- normal에 비해 자주 일어나는 현상이 아니기 때문에 false alarm 방지 대비 sparsly constrain 추가!
- temporal smoothness term
5. Experiments

- ex) traffic accidents, crimes, illegal activties
- metrics : ROC curve, AUC
5.2. Comparison with the State-of-the-art
- 비교군
- Binary SVM Classifier
- Lu et al : dictionary based approach
- Hasan et al : deep auto-encoder based approach
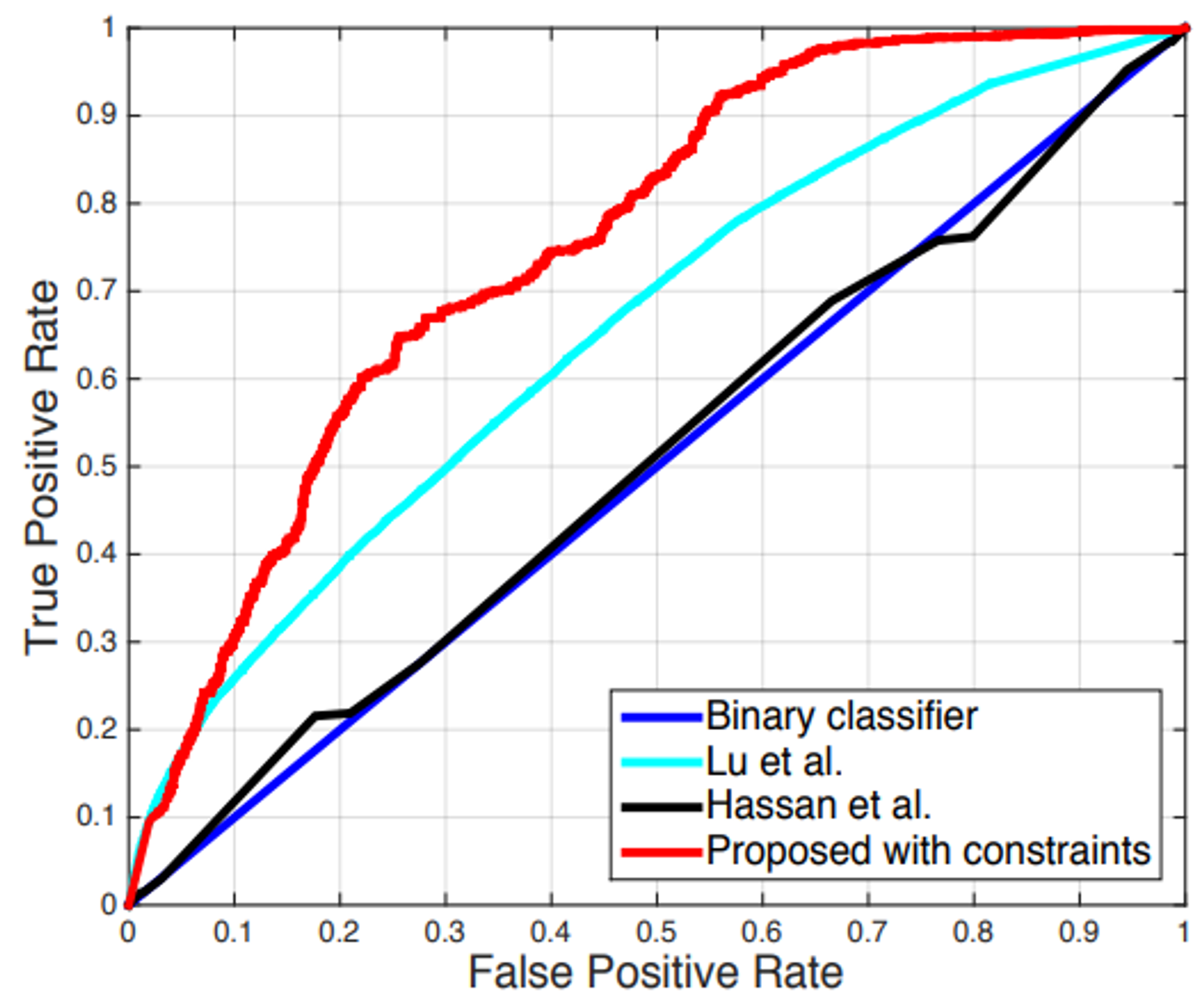
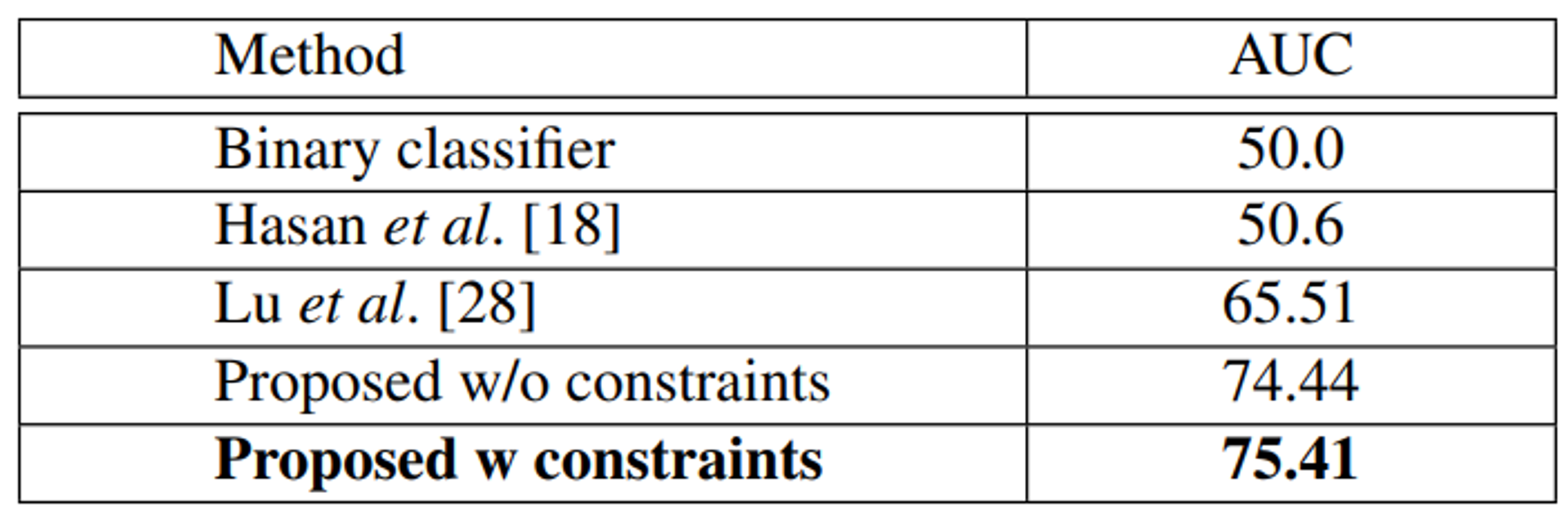
- 빨간색 outperforms the existing methods
- Binary classifier
- real world surveillance video에 완전 별로
- 사용한 데이터셋이 전혀 가공하지 않은 긴 동영상인데 그 중 anomaly는 짧은 시간에 일어났기 때문에, 대부분의 testing video에 대해 낮은 점수를 주었음
- Dictionary based approach
- 정상 비정상 모든 video에 대해 low reconstruction error 발생
- Deep auto-encoder based approach
- normal은 꽤 잘 학습하나, 새로운 정상 패턴에 대해 높은 anomaly score
⇒ 우리 방법론 짱!
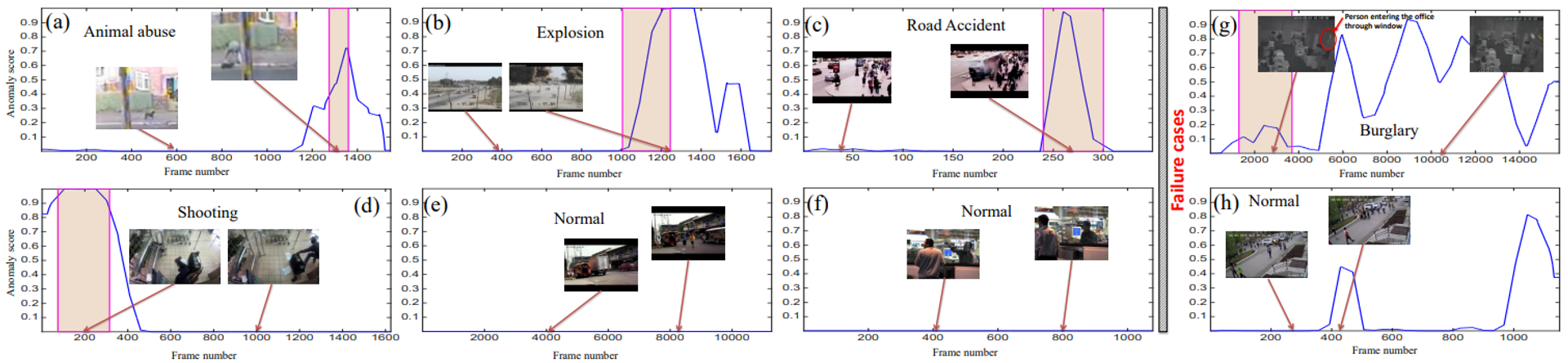
- (a)~(d) : anomalous events
- (e), (f) : normal
- (g), (h) : failure cases
- (g) : 너무 어두워서 detect 못함+ 카메라 앞에 벌레 날아다닐 때 false alarm
- (h) : 사람들이 갑자기 모여서(릴레이 레이스 보려고) false alarm
5.3. Analysis of the Proposed Method
Model training

- 가정) video level label로 이루어진 positive, negative video들이 많이 주어졌을 때, 모델이 자동으로 anomaly가 어디서 발생했는지 예측하는 것
- anomaly가 있는 segment에서 high score을 만들어내야함
- iteration이 커질수록, 모델이 더 정확하게 anomaly 위치를 찾아내는 것을 확인할 수 있음
⇒ video level label을 사용했는데도, 모델은 anomaly가 발생하는 temporal location을 찾아낼 수 있다!!!!
False alarm rate
- 실제 상황을 보면 감시 카메라의 대부분이 normal 상황임
- 고로 robust한 anomaly detection method가 되기 위해서는 low false alarm rates on normal video
- 고로 normal video만 가지고 성능을 평가해봄

- 우리꺼 굿