
No.1 일대일 화상영어 링글
스탠퍼드 MBA출신이 만든 1:1 화상 영어 명문대 원어민 튜터의 똑똑한 수업을 경험하세요!
www.ringleplus.com
공모전을 준비하면서 진행했던 활동 하나를 올려보려고 한다.
서비스 기획 공모전이었는데 배경 분석에서 이용자들의 리뷰 데이터로 워드클라우드를 만들어 어떤 점이 가장 큰 이슈인지 제시하면 좋을 것 같다는 생각이 들어 진행하였다.
안드로이드에서 주로 사용하는 플레이스토어와 애플에서 사용하는 앱스토어, 그리고 링글 홈페이지에 존재하는 리뷰 데이터들을 크롤링하여 사용하였다.
간단한 전처리를 진행한 뒤 링글 로고에 맞게 이쁜 워드클라우드 사진을 뽑아냈다.
전체 코드는 아래에 있다.
GitHub - white-bean/Data-Science: Study Data Analysis
Study Data Analysis. Contribute to white-bean/Data-Science development by creating an account on GitHub.
github.com
1. 플레이스토어 크롤링

파이썬의 selenium와 beautifulsoup 라이브러리를 이용해서 플레이스토어에 올라와있는 리뷰 데이터를 크롤링하였다.
selenium으로 동적인 부분을 제어했고 데이터를 가져올 때는 beautifulsoup을 이용하였다.
사실 전체를 selenium으로 해도 되나 지금까지 경험을 바탕으로 봤을 때 데이터 가져오는 것은 beautifulsoup이 훠어어어얼씬 빠르다.
하지만 링글처럼 데이터 수가 적을 때는 selenium으로 진행해도 충분하다.
아래와 같이 크롤링을 완료하였다. 자세한 코드는 깃허브를 참고하면 될 것 같다.
다음과 같이 일자, 연도, 월, 일, 유저이름, 별점, 그리고 리뷰 내용을 담은 데이터프레임을 생성하였다.
2. 앱스토어 크롤링
앱스토어 리뷰데이터의 경우 10개도 되지 않았다.
그래서.... 코드로 만들기 귀찮다는 생각이 스쳐 지나가버려서 그냥 수기로 데이터를 입력했다...ㅎ

3. 스토어 리뷰데이터 전처리
전처리는 크게 2가지로 진행했다.
1) 클렌징
2) 토큰화
1) 클렌징
리뷰데이터를 보면 이모티콘도 있고 특수문자도 있고 숫자도 있다.
정확도를 높이려면 이러한 것들을 지워주는 작업이 필요하다.
# 특수문자 제거
df["content"] = df["content"].str.replace(pat=r'[^\w :]', repl=r'', regex=True)[^\w]는 모든 특수문자를 의미하는데 거기에 나는 공백과 :을 추가함으로써 이 둘은 지워지지 않도록 했다.
df는 리뷰데이터를 담고 있는 데이터프레임이고 content는 이 데이터 중 리뷰 내용에 해당하는 열이다.
2) 토큰화
클렌징을 진행한 후 한글을 품사에 따라 나눠주는 토큰화를 진행하였다.
나는 형태소 분석기로 konlpy 라이브러리의 okt를 사용하였다.
konlpy를 설치하는 법은 다른 블로그에서도 많이 다루고 있으니 참고하면 좋을 것 같다.
나는 아래 블로그를 참고했다.
https://data-scientist-brian-kim.tistory.com/79
[Window10에서 KoNLPy 설치하기] 이제 삽질은 그만!! ^^
이번 포스팅에서는 많은 분들이 애를 먹고 있는 문제 중 하나인 KoNLPy 패키지 설치에 관해 정리해보려 한다. 필자 또한 책 또는 구글에 나온대로 해당 패키지를 설치했지만 한 번에 제대로 설치
data-scientist-brian-kim.tistory.com

okt = Okt()
word_list = df['content']
sentences_tag = []
for sentence in word_list:
morph = okt.pos(sentence, norm=True, stem=True)
sentences_tag.append(morph)먼저 okt의 pos 함수를 이용해 품사 태깅을 진행한다.
noun_list = []
for sentence in sentences_tag:
for word, tag in sentence:
if tag in ["Noun"]:
noun_list.append(word)명사만 이용하는게 제일 낫다고 판단하였기 때문에 이 중에서 명사만 뽑아 리스트에 넣었다.
그리고 잠시 대기~
4. 링글 홈페이지 리뷰 크롤링
위 사진은 링글 홈페이지에서 볼 수 있는 페이지이다.
이 블로그를 작성하는 시간 기준 380,153개의 후기가 존재한다고 나와있는데 실시간으로 계속 반영이 되는 것 같다.
사실 홈페이지에 나와있는 후기이기에 좋은 내용만 있는게 아닐까 싶었지만 일단 그대로 진행하였다.
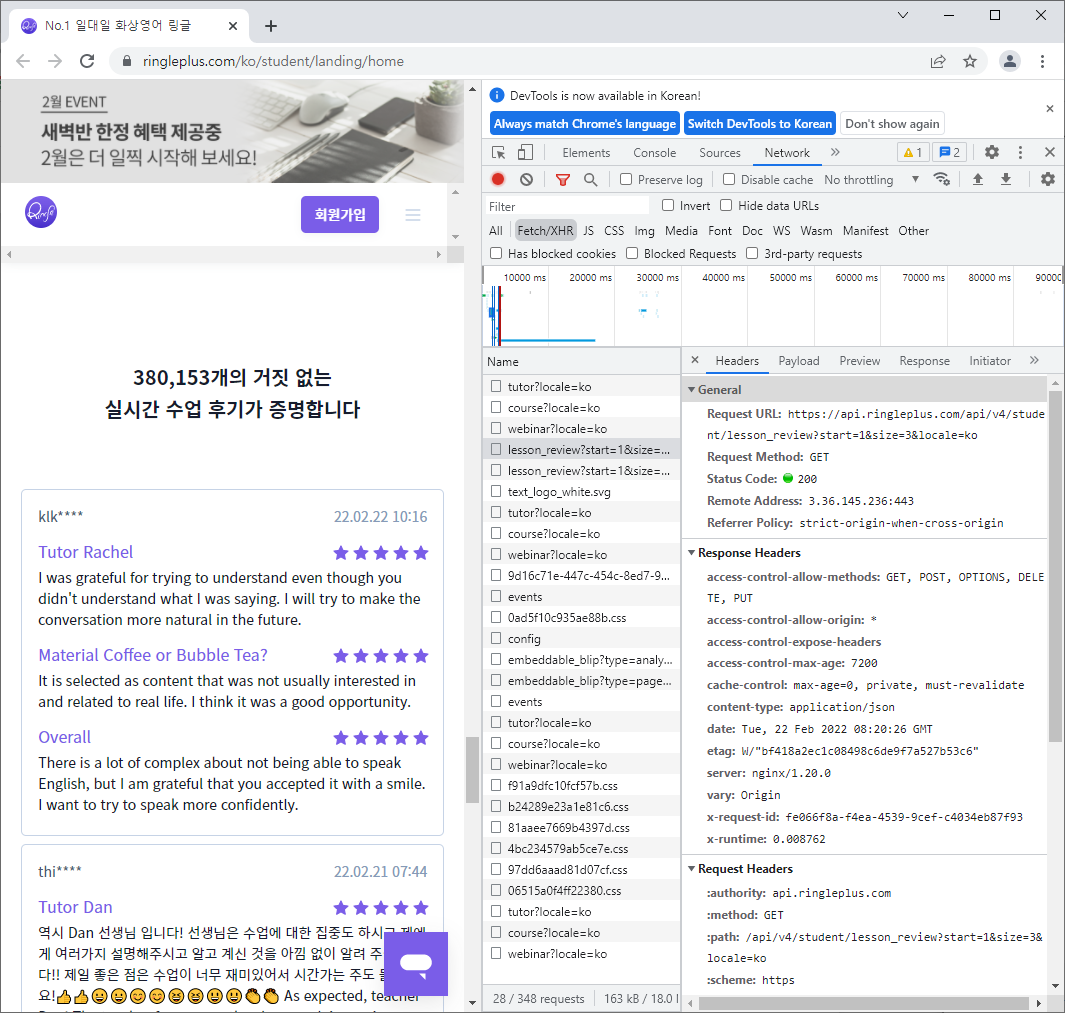
해당 웹페이지에서 F12를 누르고 network 창에 들어가면 리뷰데이터를 가져와 웹에 랜더링하는 작업을 볼 수 있다.
이 과정에서 request URL을 찾을 수 있었는데 해당 URL을 보면 다음과 같다.
https://api.ringleplus.com/api/v4/student/lesson_review?start=1&size=3&locale=ko
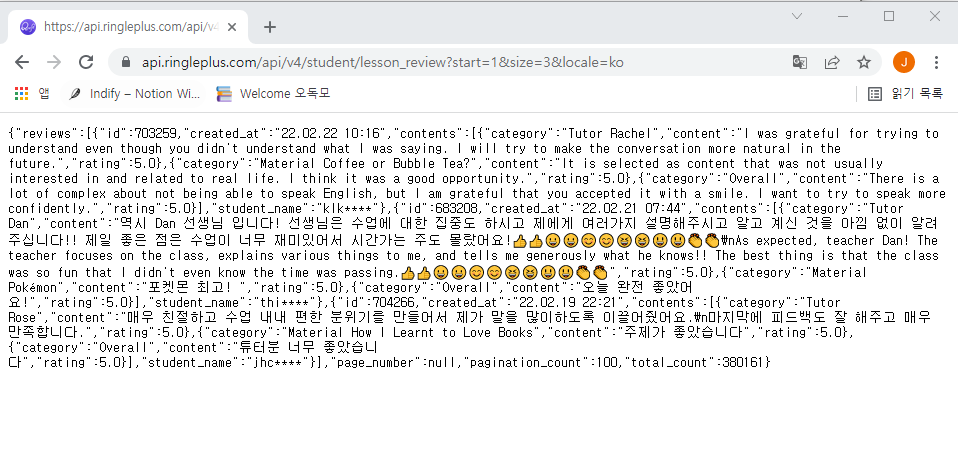
위 URL을 주소창에 쳐서 접속하면 다음과 같은 형식의 데이터를 얻을 수 있다.
json 형식인 것 같다.
start 인자는 페이지인 것 같고 size는 리뷰 개수 같다.
이 URL을 이용해 2000개의 리뷰에 접근할 수 있었다.
data=requests.get('https://api.ringleplus.com/api/v4/student/lesson_review?start=1&size=2000&locale=ko').json()
df = json_normalize(data['reviews'])requests 라이브러리를 통해 start를 1, size를 2000으로 한 URL에 접근한 뒤
json_normalize 함수를 이용해 json을 dataframe으로 변환하려고 했다.
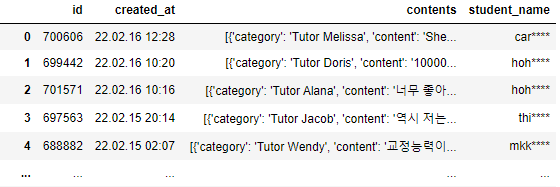
하지만 결과는 위와 같이 contents라는 항목이 잘 분류가 안되었는데 그 이유는 같은 한 개의 아이디가 3개의 contents를 가지고 있기 때문이다.
사실 2개도 있다. 그래서 뒤에 따로 처리를 해준다.
따라서 id와 created_at과 student_name을 contents의 길이에 맞게 개수를 늘려 리스트에 넣고
contents에 해당하는 데이터만 따로 json_normalize를 통해 dataframe으로 만든 뒤
id, created_at, student_name이 들어있는 리스트를 붙여주었다.
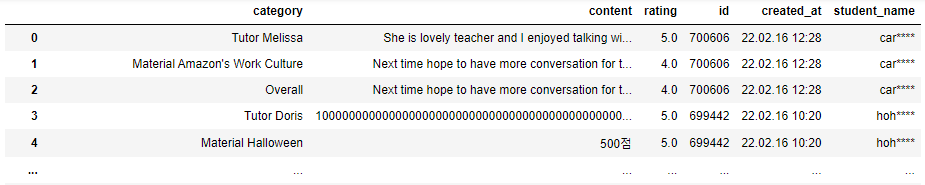
그럼 이렇게 이쁘게 정리된 dataframe을 얻을 수 있다.
5. 링글 홈페이지 리뷰 전처리
이 리뷰 데이터도 위에서 진행한 전처리처럼 똑같이 진행한다.
1) 클렌징
2) 토큰화
1) 클렌징
이번 데이터에는 특별하게 영어로 된 리뷰가 정말 많다.
사실 영어와 한글을 나누어 클렌징, 토큰화 등을 진행한 후 워드클라우드를 생성할 수도 있었겠지만....
미관상의 이유로 한글만 사용하기로 결론지었다.
그래서 한글만 남기고 다 지우는 작업을 진행했다.
import re
review_list = df["content"].str.replace(pat=r'[^ ㄱ-ㅣ가-힣]+', repl=r'', regex=True)띄어쓰기와 한글만 남기고 모두 지우는 작업이다.
2) 토큰화
토큰화 부분은 위에 진행한 방식과 동일하다.
sentences_tag = []
for sentence in review_list:
morph = okt.pos(sentence, norm=True, stem=True)
sentences_tag.append(morph)okt의 pos 함수를 이용해 품사 태깅을 진행하고
for sentence in sentences_tag:
for word, tag in sentence:
if tag in ["Noun"]:
noun_list.append(word)그 중 명사만 뽑아 위에서 생성했던 noun_list에 추가한다.
여기서 더 나아가
# 명사 중 글자 수 2개 이상인 것만 추출
noun_list = [n for n in noun_list if len(n) > 1]물론 '꿈'같은 1개의 글자 수를 갖는 의미 있는 명사도 존재하지만 그렇지 않은 명사가 훨씬 더 많았기에 명사 중 글자 수가 최소 2개 이상인 것만 남기고 모두 삭제하였다.
# stopwords 정의
stopwords={'다만','리기','듭니','일단','조금','겨우','바이','원래','그냥','어차피','대로','수도','그대로','무슨','무엇','정말',
'지금', '번은','해당','다시','만날','작렬','보고','어찌','일인','달동','보이지','아예','번의','알바로','하니','더욱',
'애애','화기','당장','제발','하나요','주전','게다가','도저히','도대체','네이티','이예','기네','아무','이얼','이친',
'투터','일리','계로','오지','가지','다소','주시','만큼','해주시','부랴부랴','좀더', '대해','정말','매우','다만','아주',
'대한'}
noun_list = [i for i in noun_list if i not in stopwords]그리고 차마 전처리되지못한 의미 없는 한글들을 따로 stopwords로 정의해 워드클라우드에서 나타나지 않도록 하였다.
6. 워드클라우드
# 워드클라우드 색 지정
def color_func(word, font_size, position,orientation,random_state=None, **kwargs):
return("hsl({:d},{:d}%, {:d}%)".format(np.random.randint(200,293),np.random.randint(74,100),np.random.randint(30,69)))나는 링글의 보라색에 진심이었기에 따로 워드클라우드에 색을 지정하는 법을 알아내서 진행하였다.
Word cloud 원하는 색으로 꾸미기 (word cloud customize color)
분석대회를 끝내고, 발표자료를 준비하는데 워드클라우드로 시각화를 한 이미지가 생각보다 안 예쁘더랍니다. ppt 테마 색 같은 걸 정해놓은 경우엔 미적 감각이 없는 제가 봐도, 이런 부조화가
wannabe00.tistory.com
위 블로그를 참고하였다.
그리고 링글 로고를 다운로드하여 마스킹하였고
보여주는 단어 수는 1000개로 하였다.
코드는 아래와 같다.
# 워드클라우드 마스킹
test = np.array(Image.open('test.png'))
counts = Counter(noun_list)
tags = counts.most_common(1000)
wordcloud = WordCloud(font_path="NanumGothic.ttf",
background_color='white',width=800, height=600, color_func = color_func, mask=test, max_font_size=100)
#print(dict(tags))
cloud = wordcloud.generate_from_frequencies(dict(tags))
plt.figure(figsize=(10,8))
plt.axis('off')
plt.imshow(cloud)
plt.show()그렇게 해서 나온 결과는 아래와 같다.

예쁘다~

'Data Science' 카테고리의 다른 글
| [핸즈온 머신러닝] 규제 (0) | 2021.04.04 |
|---|---|
| Selenium으로 인스타그램 크롤링하기 (0) | 2021.02.20 |
| 40 Examples to Master Pandas (1) : 1번~10번 (0) | 2021.01.29 |